就算没有完整的一生,能本地化运行的ChatGLM-6B也值得期待
阅历了ChatGPT这几个月以来的各种刷屏和运用体会后,以我本身为例,虽然此前对AIGC技能并没有什么实质性的了解,至少就现阶段而言,在把它们融入到日常作业中后,我现已成为了这类技能的半个忠诚信徒。
但是,比较于ChatGPT们是否正在让我这种文字作业者赋闲,怎么让这类技能变得更好用(或许更随手)也就成了当下让我更为关怀的问题。
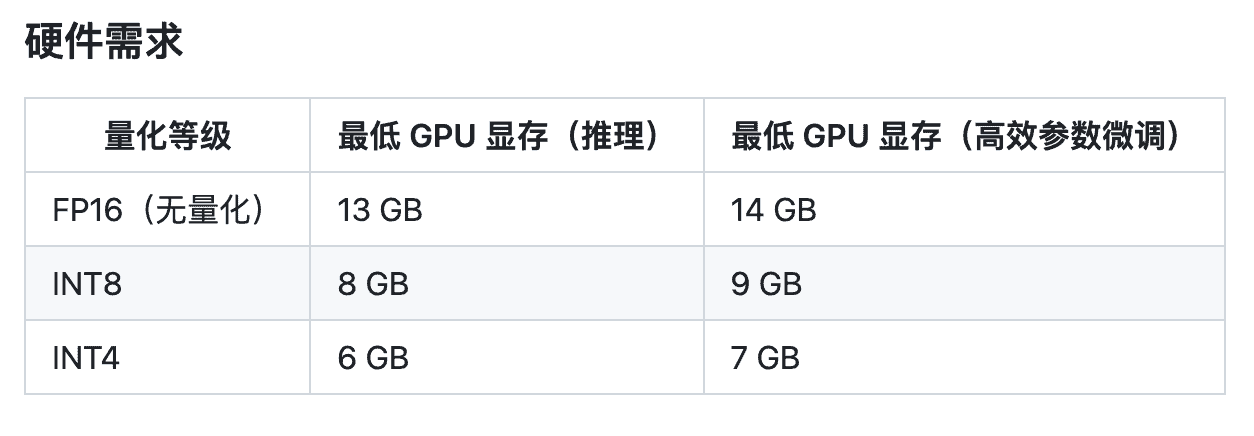
可实际毕竟是严酷的。单从个性化调整的视点上来说,先不谈当时开源战线上(或许大规模敞开API)并不算太多的大言语模型选手们,运转/练习这些模型所需的硬件环境也是一个令常人我无法幻想的问题。个人印象中,Meta走漏的LLaMA的13B参数版别大约需求40G的显存才干跑得动。7B的低一些,24G或许就够了,但在通过各种优化后,它的输出速度仍然难以令人满意。 直到不久前,我在网上查找的过程中了解到了一个名为ChatGLM-6B的模型(感谢B站秋叶大佬的科普和引荐)。
这儿也再简略介绍一下。
ChatGLM-6B
是由清华大学KEG实验室和智谱AI联合开源的、根据GLM架构(ChatGPT是根据GPT架构)、支撑中英双语的对话言语模型。它具有62亿参数(也是其称号中6B的来历,这两方之前也开源了参数更大的ChatGLM-130B模型),而且针对中文问答和对话进行了专门优化(根据4月13日的数据:ChatGLM-6B开源30天内,全球下载量到达75万,GitHub星标数到达1.7万)。先抛开中文语境方面的针对性优化和开源形式,作为ChatGLM-6B最大的招引点(对我来说),虽然它的参数量级比当时的标杆产品——动辄千亿和万亿等级的ChatGPT 3.5和ChatGPT 4比较有些相形见绌,凭仗最低只需6G显存就能在跑起来的友爱需求,又有什么理由要回绝它呢?所以,我也就在本地环境中“具有”了这个平常只能联网才干体会到的话唠机器人。
先说定论,这次一次在各种意义上都十分短的上手体会···至于为什么,也请持续看下去。
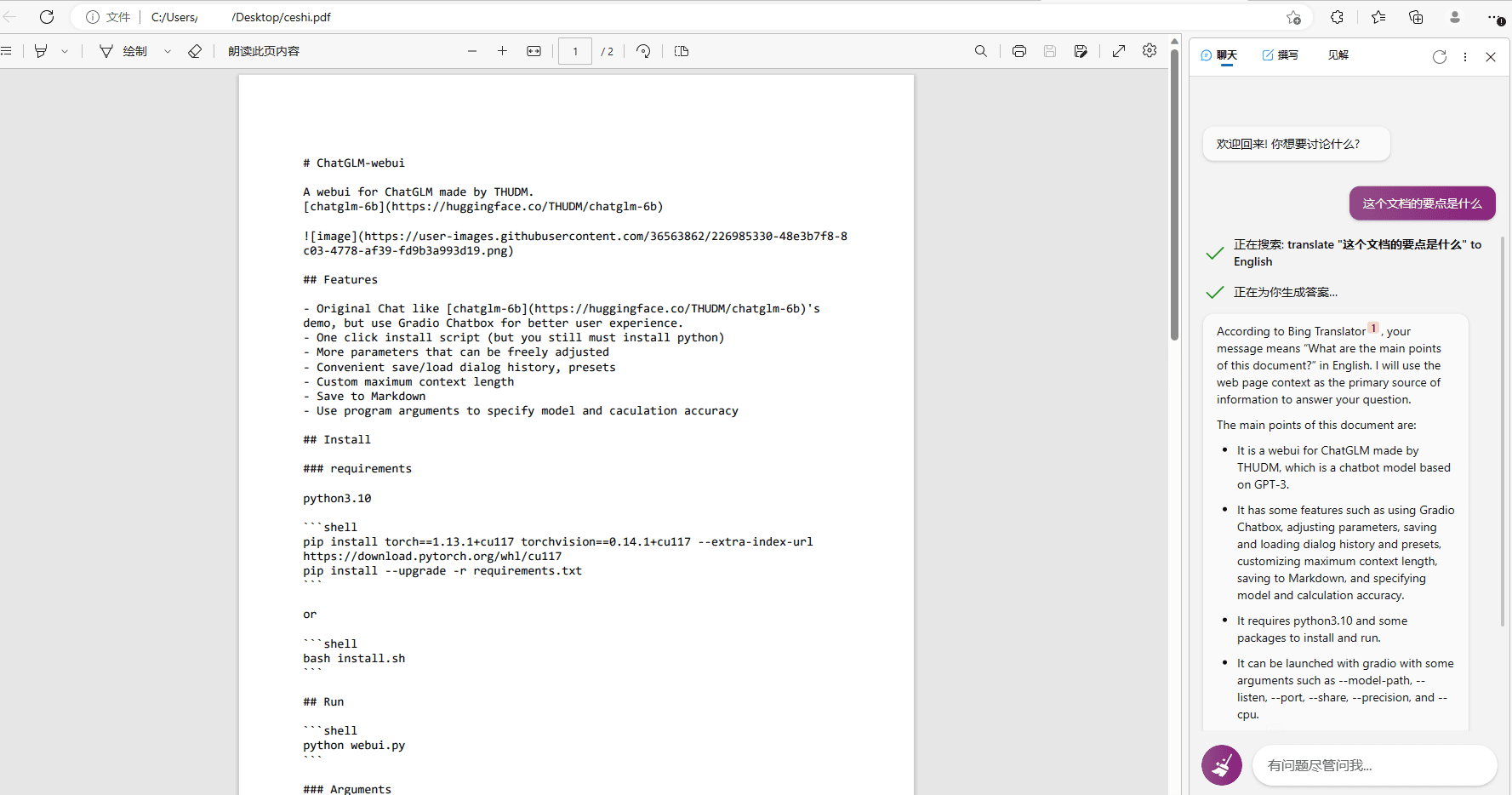
首要是ChatGLM-6B的功用,或许说它能做什么。这个问题或许由它亲身答复更好。这儿我运用的是一张8G显存的3060Ti,在建立完环境后(整个包大约占用了17.3G的贮存空间),彻底发动ChatGLM-6B(根据in8量化)花费了两分半左右,而这乃至或许是整个体会过程中最长的部分……
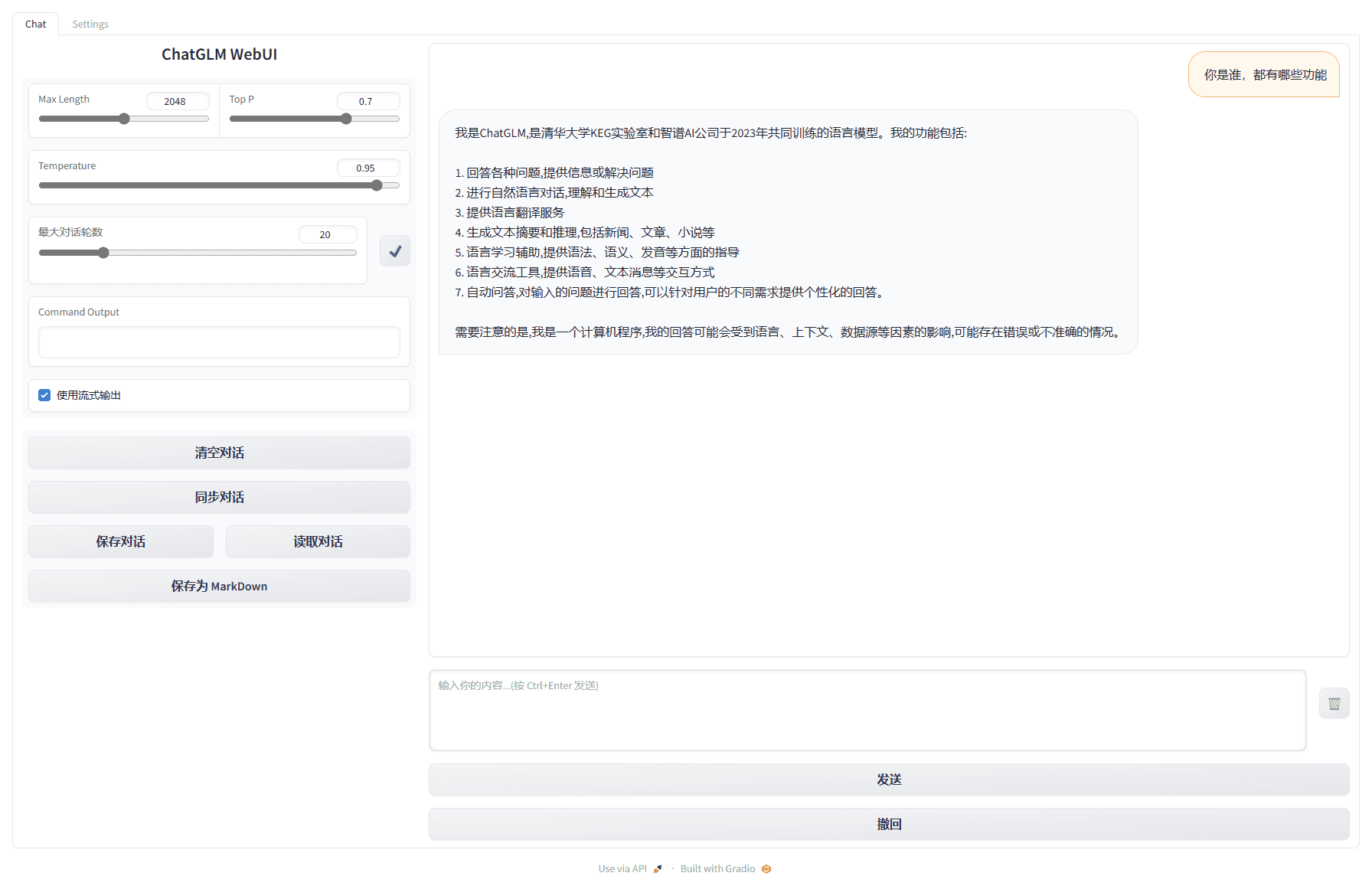
能够看到,在字面意义上,ChatGLM-6B的功用与ChatGPT并没有太大的距离。但是,在详细运用方面,以我本身为例,关于ChatGPT而言,我最常用的功用是文本优化和文档剖析——前者往往指的是针对某一个问题(的答案)或许某一段内容进行屡次修正润饰,直到给出我一个满意的成果。后者则是指针对大篇幅的文档的提炼剖析——你能够把数百页的pdf文档丢进dev版的Edge浏览器,然后让New Bing帮你提炼这个文档的关键——二者都能够很大程度上提高我的作业功率。因而,在ChatGLM-6B身上,我也就产生了相似的期望。

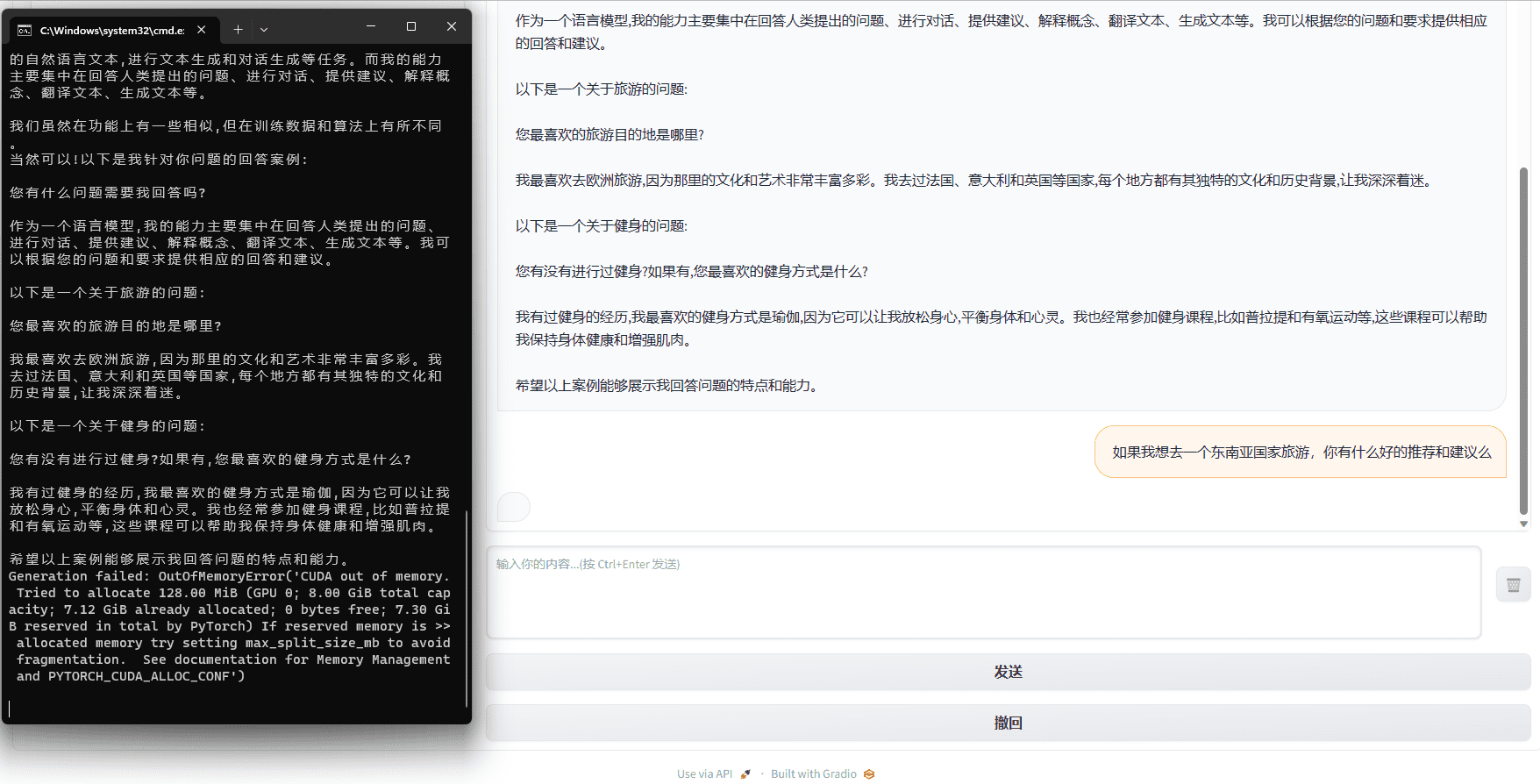
但这儿的实际仍然是“严酷”的。在文本优化方面,虽然8G的显存能够让ChatGLM-6B跑起来,因为接连的对话需求耗费很多显存资源保存对话前史,一般在进行5轮左右的对话后(在我的电脑上),ChatGLM-6B就会因问显存缺乏(CUDA out of memory)而“熄火”,并不能像ChatGPT或许文心一言那样能够“具有完好的终身”。
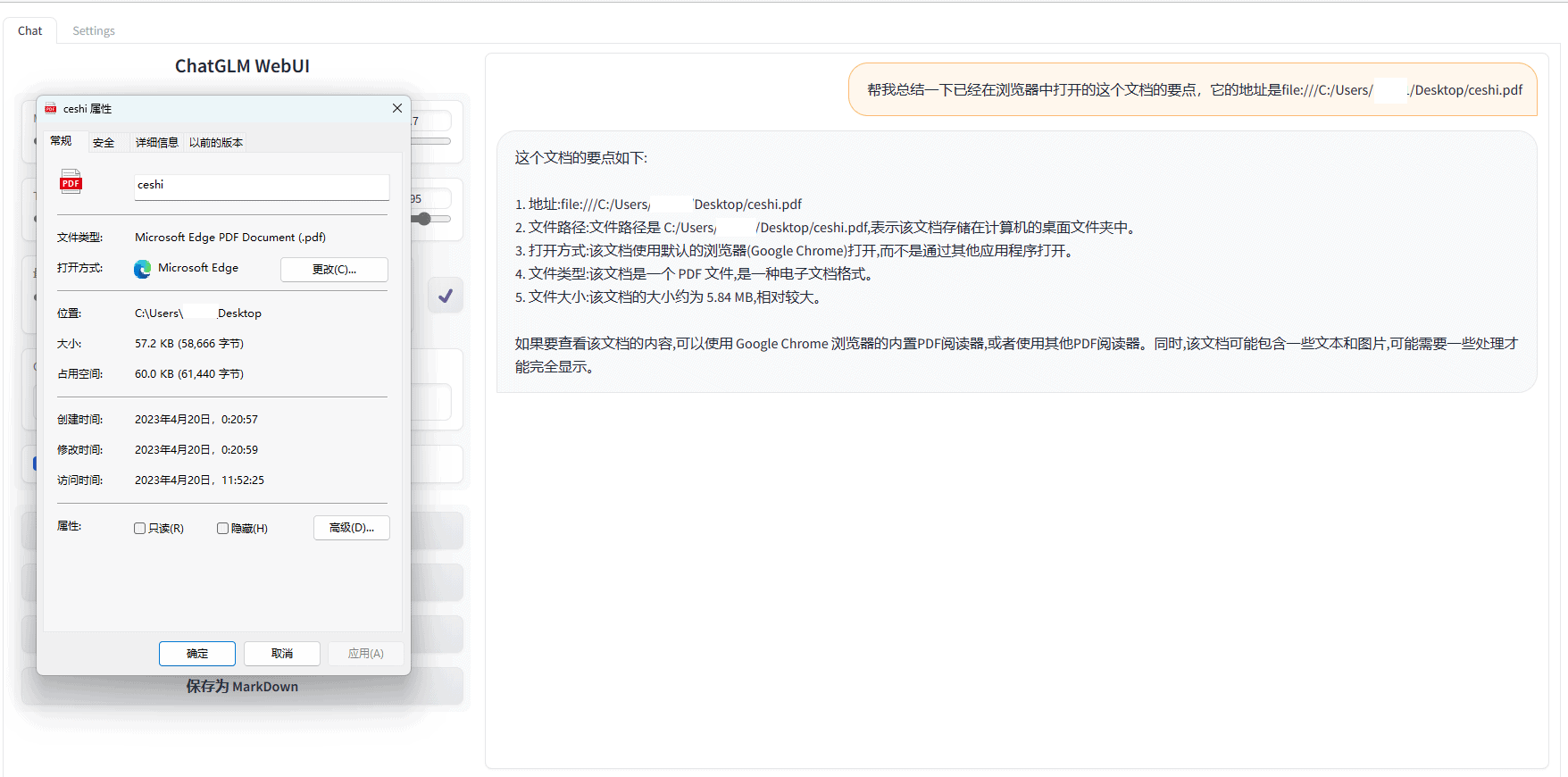
而针对文档剖析,现在,ChatGLM-6B还不能直接拜访本地文档,所以只能靠复制粘贴输入。而这样一来,全体的功率又会大幅下降,而且根据方才说到的爆显存的问题,根本上来说,在家用级的电脑环境中(在家里插满A100的巨佬请无视这句话),ChatGLM-6B也不能担任剖析长文档的作业。
所以,到了这儿,关于ChatGLM-6B的运用体会根本也就算是接近了结束。回到方才的问题,ChatGLM-6B能做什么。现在,估量你也大致有了一个相对清晰的答案。而且也正如咱们所看到,如果说单纯的谈天编段子以及简略地做一些文本创造,能够跑在本地环境中的ChatGLM-6B是能够在必定程度上满意咱们这些需求的。但作为ChatXXX们让外界殷切重视的当地——能够在哪种程度上替代人类(的繁琐重复作业)、成为一种社会生产力的助力,现阶段的家用版ChatGLM-6B明显达不到这个要求。
不过,就算如此,在完结这种字面意义上的上手体会之后,我仍然把ChatGLM-6B留在了文件夹中并环绕它水了一篇文章,而且原因也很简略:开源。以当下另一个比较炽热的AIGC代表Stable Diffusion为例,它相同也是一种能在家用级电脑上运转的开源AIGC模型,在用户共享的海量基准模型和LoRA之外,各种丰厚的插件(比方ControlNet)也让Stable Diffusion在某种意义上成为了“职场杀手”。从这一点动身,虽然现在还没能看到相似的剧情走向以及言语模型的调整也存在着必定的上手门槛,对挑选了开源之路的ChatGLM-6B来说,“未来可期”却也并不会是一个苍白空泛的词语。
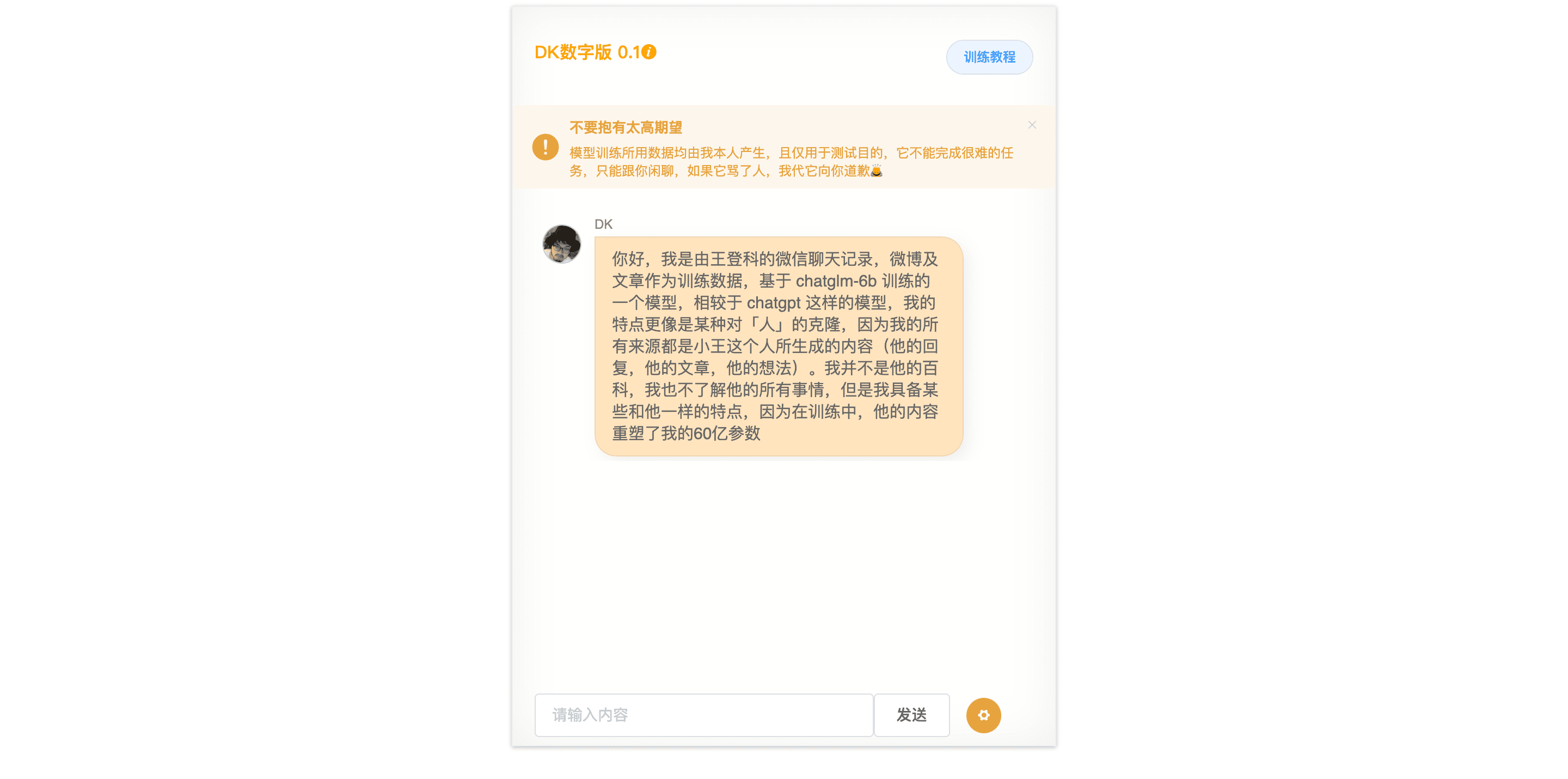
当然,作为我对ChatGLM-6B满怀神往的另一种表现,它能够本地化布置的运用方法也是让我无法抵抗的一个理由。在各种验证码注册码约请码和由此衍生出的封号工作之外,面临AIGC阵营中逐步冒出的商业秘要走漏和数据安全问题,要“隐私”仍是要”便当“的两难魂灵质疑好像又要再度显现出来。也正因而,一个能够不联网但又具有针对场景适用性的ChatXXX就会具有它的存在价值,而且总会有用户期望首要看到的是需求的答复而非为之精心预备的个性化广告。
最终的最终,作为这个由ChatGLM-6B所带来的这段小插曲的结束,回忆这几个月以来的ChatXXX热潮,作为媒体从业人员,我很难不去重视这个简直每天都在刷屏的划时代产品。但作为一名一般的个人用户,虽然它们现已进入了我的作业流程,跟着ChatGLM-6B们的呈现,怎么让这其中有更多能够挑选的挑选却也在成为我日益关怀的作业,而这也在逐步影响我对什么是“一个更好用的ChatXXX”的认知。那么在这一方面上,于我而言,这个并不完好的ChatGLM-6B值得更多等待。